2015-10-30 22:06:51
北京用友远程维护收
用友财务软件中了.ro
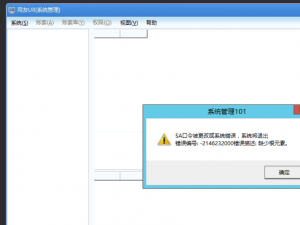
用友U8+:错误编号:-
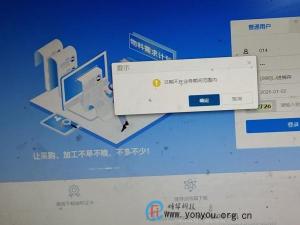
用友T+软件发现登录
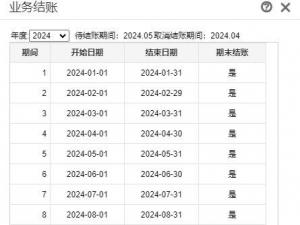
用友T+年末处理之一
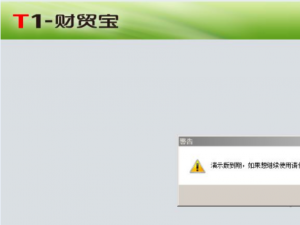
用友T1软件登录提示
关于畅捷通用友T1产
用友T+软件如何建立